Amazon EMR上でAsakusa Frameworkを利用する¶
- 対象バージョン: Asakusa Framework
0.9.0以降
この文書は、 Amazon Web Services (AWS) が提供するクラウド環境上のHadoopサービス Amazon EMR 上でAsakusa Frameworkを利用する方法について説明します。
Attention
Amazon EMR は頻繁にバージョンアップが行われるため、バージョンによっては本書と内容が異なる可能性があります。
以降では、 Amazon Web Services を「AWS」、 Amazon EMR を「EMR」と表記します。
また、本書ではAsakusa Frameworkのデプロイやアプリケーションの実行時に、AWSが提供するストレージサービスである Amazon Simple Storage Service (Amazon S3)を利用します。以降では、 Amazon Simple Storage Service を「S3」と表記します。
AWSが提供する各サービスの詳細はAWSが提供するドキュメントを参照してください。
はじめに¶
本書では、 Asakusa Framework スタートガイド の説明で使用したサンプルアプリケーションを例に、EMR上でバッチアプリケーションを実行するまでの手順を説明します。
また、ここではアプリケーションのデータ入出力をS3に対して行うよう設定します。
EMRと関連サービス利用環境の準備¶
EMRやS3を利用するための環境を準備します。
本書で示す手順に従ってEMR上でAsakusa Frameworkを利用するためには、以下の準備を行う必要があります。
- AWSへのサインアップ
- Amazon S3バケットの作成
これらの準備が整っていない場合、以下に示すドキュメントなどを参考にして、EMRを利用するための環境を準備してください。
- AWSへのサインアップ
- アカウント作成の流れ | アマゾン ウェブ サービス(AWS 日本語)
- Amazon S3バケットの作成
- Amazon Simple Storage Service の使用開始 ( Amazon S3 入門ガイド )
AWSサービスの操作¶
EMRやS3など、AWSが提供する各サービスに対する操作には以下のような方法があります。
- AWSマネジメントコンソール (以下「コンソール」)を使用する方法
- AWSコマンドラインインターフェイス (以下「CLI」)を使用する方法
- AWSが提供するSDKを利用する方法
- 各サービスが提供するWeb Service APIを利用する方法
それぞれのツールで実現可能な操作が多少異なりますが、本書の範囲内ではコンソールやCLIですべての操作が可能です。 本書では操作手順の説明においてコンソールとCLIの操作を簡単に紹介します。
AWSで利用可能な操作の詳細やツールのセットアップ方法などは、各サービスのドキュメントを参照してください。
Asakusa Framework実行環境の構成とデプロイ¶
開発環境で作成したアプリケーションプロジェクトに対してEMR環境向けにAsakusa Frameworkの構成を行い、Asakusa Framework実行環境一式をデプロイします。
EMRを利用する上では、様々な方法でAsakusa Frameworkをデプロイすることができますが、ここではAsakusa FrameworkのデプロイメントアーカイブをEMRクラスター [1] の起動前にS3に配置し、EMRクラスターの起動後にこれをEMRクラスターのマスターノードにデプロイするものとします。
| [1] | Amazon EMR Management Guide の記述に基づき、EMRを利用して構築したクラスター環境をEMRクラスターと呼びます |
Direct I/Oの設定¶
バッチアプリケーションに対してEMR上でS3に対するデータ入出力を行うための設定を行います。
Direct I/Oを使ってS3に対してデータの読み書きを行うようにするため設定ファイル asakusa-resources.xml を編集します。
以下は、 asakusa-resources.xml の設定例です。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>com.asakusafw.runtime.core.Report.Delegate</name>
<value>com.asakusafw.runtime.report.CommonsLoggingReport</value>
</property>
<!-- task optimization -->
<property>
<name>com.asakusafw.input.combine.max</name>
<value>256</value>
</property>
<property>
<name>com.asakusafw.input.combine.tiny.limit</name>
<value>1048576</value>
</property>
<property>
<name>com.asakusafw.reducer.tiny.limit</name>
<value>1048576</value>
</property>
<!-- library cache -->
<property>
<name>com.asakusafw.launcher.cache.path</name>
<value>target/libcache</value>
</property>
<!-- Direct I/O base settings -->
<property>
<name>com.asakusafw.directio.root</name>
<value>com.asakusafw.runtime.directio.hadoop.HadoopDataSource</value>
</property>
<property>
<name>com.asakusafw.directio.root.path</name>
<value>/</value>
</property>
<property>
<name>com.asakusafw.directio.root.fs.path</name>
<value>@directioRootFsPath@</value>
</property>
<!-- Direct I/O settings for EMR/S3 -->
<property>
<name>com.asakusafw.directio.root.output.staging</name>
<value>false</value>
</property>
</configuration>
See also
asakusa-resources.xml で記述するDirect I/Oの設定について詳しくは、 Direct I/O ユーザーガイド を参照してください。
また、上記の設定ファイルの例ではDirect I/O以外にいくつかの実行時設定を行なっています。詳しくは、 Hadoopパラメータの設定 を参照してください。
ここでは上記の asakusa-resources.xml をダウンロードして、アプリケーションプロジェクト配下のディレクトリ src/dist/emr/core/conf に配置してください。
mkdir -p src/dist/emr/core/conf
cp $HOME/Downloads/asakusa-resources.xml src/dist/emr/core/conf
Hint
上記設定に含まれる @...@ の文字列は、 Framework Organizer Plugin の機能を利用して
デプロイメントアーカイブ作成時に環境に合わせた値に置換します。
上記の設定ファイルの例では、プロパティ com.asakusafw.directio.root.fs.path の値 @directioRootFsPath@ はデータ入出力に利用する、S3上のパスに置換します。詳しくは次項を参照してください。
デプロイメント構成の設定¶
EMR向けの構成を持つデプロイメントアーカイブを作成するための設定を行います。
See also
デプロイメントアーカイブやデプロイメント構成の編集について詳しくは、 Asakusa Framework デプロイメントガイド を参照してください。
ここでは、サンプルアプリケーションのプロジェクトにEMR向けのデプロイメント構成用のプロファイル emr を作成するためビルドスクリプト build.gradle を編集します。
asakusafwOrganizer {
profiles.emr {
assembly.into('.') {
put 'src/dist/emr'
replace 'asakusa-resources.xml', directioRootFsPath: 's3://[mybucket]/app-data'
}
}
}
Attention
上記例を参考に設定ファイルを作成する際は、必ず directioRootFsPath の値を実際に使用するS3バケットのパスに置き換えてください。
ここでは標準の設定に対して、EMR向けのプロファイルとして profiles.emr ブロックを追加しています。
assembly.into('.') 配下は先述の Direct I/Oの設定 で説明した設定ファイルを put によってデプロイメント構成に加えています。
このとき、 asakusa-resources 内で定義したDirect I/O のファイルシステムパスの値 directioRootFsPath を指定したS3バケット上のパスに置換するための設定を定義しています。
directioRootFsPath の値は、アプリケーションのデータ入出力を行うS3バケット上のパスになります。
使用する環境に応じて、適切なパスに変更してください。
特にバケット名の部分( [mybucket] )は必ず変更する必要があります。
デプロイメントアーカイブの生成¶
Akakusa Frameworkの実行環境一式を含むデプロイメントアーカイブを作成します。
デプロイメントアーカイブを作成するには、アプリケーションプロジェクト上でGradleの assemble タスクを実行します。
./gradlew assemble
デプロイメント構成の設定 を行った状態でデプロイメントアーカイブの生成を行うと、 build ディレクトリ配下に標準のデプロイメントアーカイブに加えて、 asakusafw-$project.name-emr.tar.gz というファイル名で emr プロファイルに対応したデプロイメントアーカイブが生成されます。
デプロイメントアーカイブをS3に配置¶
デプロイメントアーカイブの生成 で作成したデプロイメントアーカイブファイル asakusafw-$project.name-emr.tar.gz をS3に配置します。
コンソール¶
S3に対するファイルアップロードは AWSマネジメントコンソール から実行することができます。
コンソールを使ってS3にファイルをアップロードする手順の例は、 バケットにオブジェクトを追加 ( Amazon S3 入門ガイド ) などを参照してください。
CLI¶
S3に対するファイルアップロードはAWS CLIからも実行することができます。
以下AWS CLIによるファイルアップロードの例です。
aws s3 cp build/asakusafw-example-basic-spark-emr.tar.gz s3://[mybucket]/asakusafw/
S3上のファイルを表示し、正しくアップロードされたことを確認します。
aws s3 ls s3://[mybucket]/asakusafw/
Attention
上記例を参考にコマンドを入力する際は、必ずアップロード先のS3バケットのパスを実際に使用するパスに置き換えてください。
EMRクラスターの起動と確認¶
EMRを利用したHadoopクラスターのセットアップと動作確認を行います。
EMRクラスターの起動¶
コンソール¶
AWSマネジメントコンソール からEMRクラスターを起動することができます。
AWSマネジメントコンソール の画面左上のメニューから を選択する。
EMRのクラスターリスト画面で、画面上部の クラスターを作成 ボタンを押下する。
EMRクラスターの起動パラメータを入力する
コンソールで指定する起動パラメータについては、 後述の 起動パラメータ で説明しているのでこちらも参照してください。
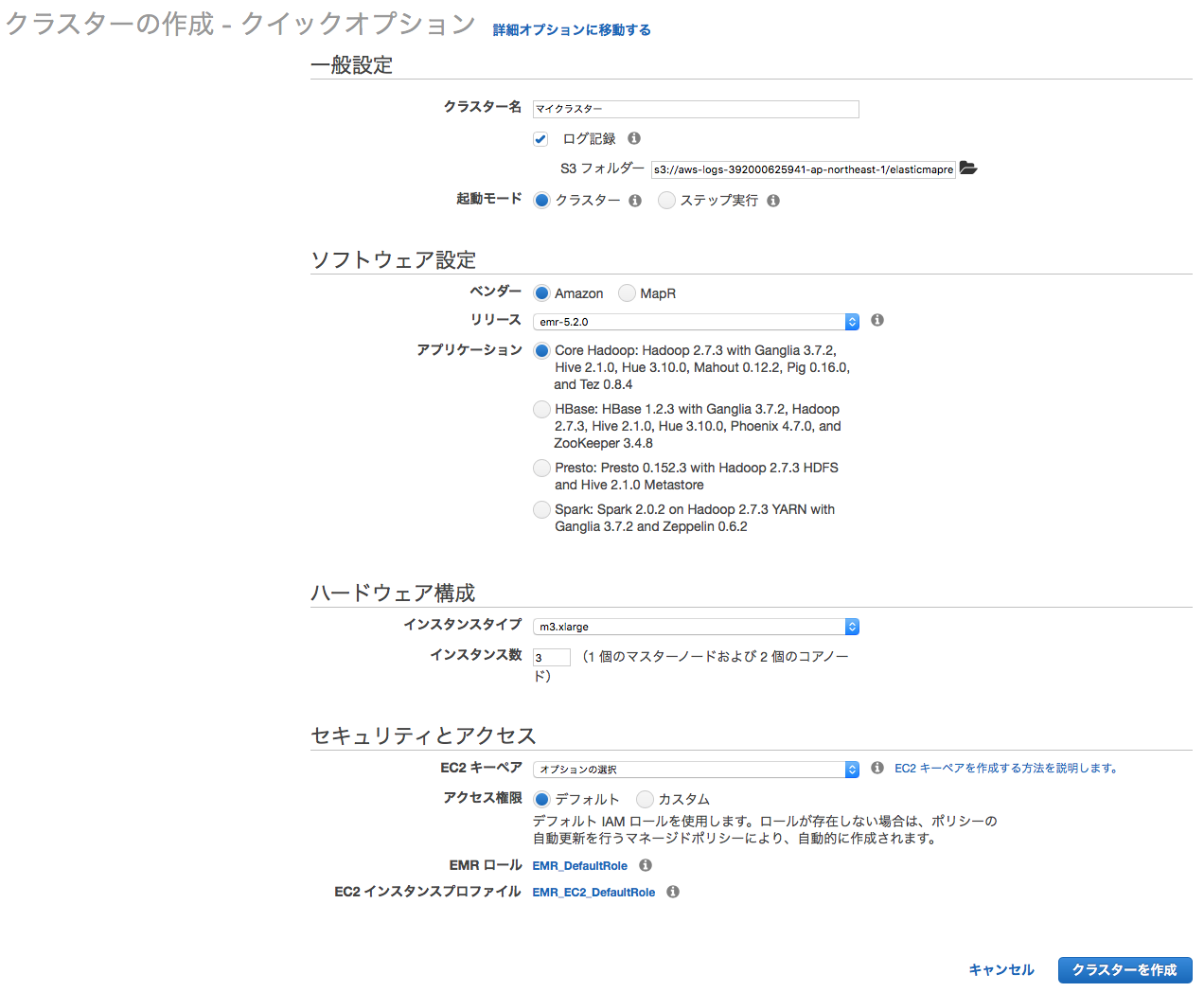
画面下の クラスターを作成 ボタンを押下する。
EMRクラスターの起動処理が開始され、クラスター詳細画面が表示されます。
CLI¶
EMRクラスターの起動はAWS CLIから実行することができます。
以下AWS CLIによるEMRクラスター起動の例です。
aws emr create-cluster \
--name asakusafw-cluster \
--log-uri s3://[mybucket]/mylog \
--enable-debugging \
--release-label emr-5.2.0 \
--applications Name=Hadoop Name=Hive Name=Spark \
--instance-type m3.xlarge \
--instance-count 1 \
--ec2-attributes KeyName=[myKey]
起動パラメータ¶
EMRクラスターの起動パラメータ(オプション)の概要を説明します。 起動パラメータの詳細やここに記載していないパラメータについては、コンソールのヘルプやEMRのドキュメントなどを参照してください。
各パラメータは以下の表記で説明しています。
コンソール上の項目名 (--CLIのオプション名 )
- クラスター名
(--name) - EMRクラスター名です。 この名前はコンソールやCLIから参照するクラスター一覧などで表示されます。
- ログ記録(S3フォルダー)
(--log-uri) - このオプションを有効にすると、EMRクラスターの各ノードのログを定期的な間隔(およそ5分ごと)でS3にコピーする機能が有効になります。 ログを配置するS3バケット上のパスを合わせて指定します。
- デバッグ
(--enable-debugging | --no-enable-debugging) - このオプションを有効にすると、コンソール上から各ログファイルを参照するためのインデックスが生成されます。
- 起動モード
(--auto-terminate | --no-auto-terminate) - 起動モードに「クラスター」
(--no-auto-terminate)を指定した場合は明示的にEMRクラスターを停止させるまでクラスターは起動し続けます。 「ステップ実行」(--auto-terminate)を指定した場合は、EMRクラスター起動時に指定したステップ(EMRクラスターで実行させる処理、詳細は後述) の実行が完了すると、自動的にEMRクラスターは停止します。 CLIを利用する場合、これらのオプションを指定しない場合は--no-auto-terminateがデフォルトで設定されます。 - リリース
(--release-label) - EMRクラスターのリリースバージョンを指定します。 指定可能なバージョンについては Amazon EMR Release Guide などを参照してください。
- アプリケーション
(--applications) - EMRクラスターに含めるアプリケーションを指定します。 このドキュメントではAsakusa on Sparkを利用するため、Sparkが含まれる項目を指定してください。
- インスタンスタイプ
(--instance-type) - EMRクラスターで使用するインスタンスタイプを指定します。
- インスタンス数
(--instance-count) - EMRクラスターで使用するインスタンス数を指定します。
Hint
デプロイメント構成の確認やアプリケーションとの疎通確認など、試験的に実行する段階ではインスタンスタイプは低コストで利用できるインスタンスタイプを使用し、ノード数も少なめで確認するのがよいでしょう。
- EC2 キーペア
(--ec2-attributes KeyName=[key-name]) - EMRクラスターの各ノードにSSH接続するためのキーペアを指定します。 デフォルトではキーペアの指定がありません。 SSH接続を行う場合は、このオプションを指定します。
クラスターID¶
EMRクラスターの起動を実行すると、コンソールやCLIの出力としてクラスターを一意に特定するためのクラスターIDが出力されます。
ステータスの確認¶
コンソールやCLIからEMRクラスターのステータスを確認することができます。
コンソール¶
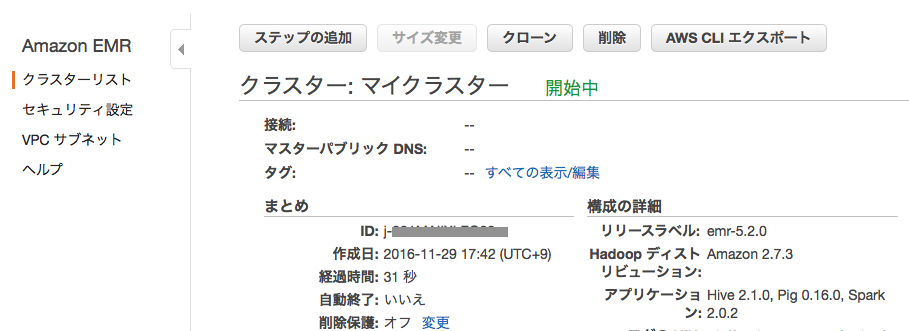
EMRクラスターの起動 後に表示されるクラスター詳細画面などで確認します。
クラスター詳細画面では、画面上部 クラスター: <クラスター名> の右側に色付きの文字列で表示されます ( 下例では 開始中 ) 。
CLI¶
以下はAWS CLIでクラスターのステータスを取得する例です。
aws emr describe-cluster --cluster-id j-XXXXXXXXXXXXX \
--query 'Cluster.Status.State'
"WAITING"
Hint
上記例の --query オプションによって全体の出力から結果ステータスの項目を抽出しています。
aws コマンドには他にも様々なオプションが利用できます。 詳しくは AWS CLI Reference の Command Reference などを参照してください。
主なステータスには以下のようなものがあります。
- 開始中 (
STARTING) - EMRクラスターが起動中
- 待機中 (
WAITING) - EMRクラスターがアイドル状態(ステップの実行待ち)
- 実行中 (
RUNNING) - EMRクラスターがステップを実行中
- 終了済み (
TERMINATED) - EMRクラスターが停止済み
EMRクラスターの起動 の手順でEMRクラスターが正常に起動し、ステータスが 待機中 ( WAITING ) になっていることを確認して以降の手順に進みます。
EMRクラスターにAsakusa Frameworkをデプロイ¶
EMRクラスターが起動したら、 デプロイメントアーカイブをS3に配置 でS3に配置したAsakusa FrameworkのデプロイメントアーカイブをEMRクラスターのマスターノードにデプロイします。
EMRクラスターに対して処理を要求するには、コンソールやCLIから「ステップ」と呼ばれる処理単位を登録します。
コンソール¶
クラスター詳細画面で以下の手順でデプロイを実行します。
画面上部の ステップの追加 ボタンを押下する

ステップの追加 ダイアログで以下の通りに入力し、 追加 ボタンを押下する
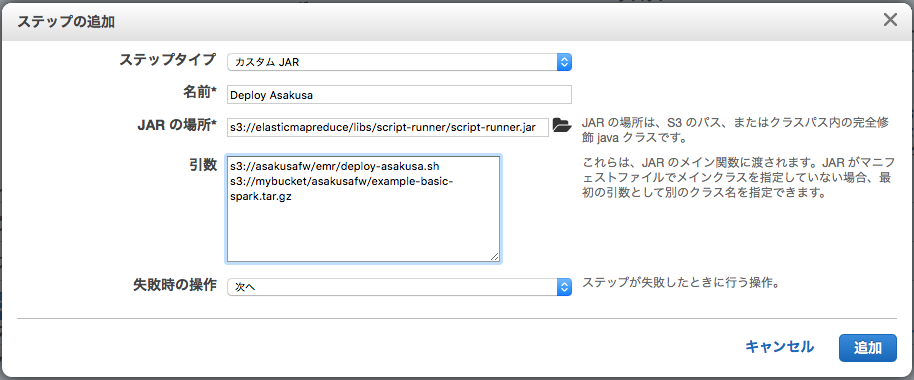
- ステップタイプ
カスタム JARを選択- 名前
任意のステップ名を入力 (この名前はステップ一覧に表示されます)
- JAR の場所
以下のS3パスを入力 [2]
s3://elasticmapreduce/libs/script-runner/script-runner.jar
- 引数
以下2つの引数を半角スペース区切りで指定 [3]
- 第1引数:
s3://asakusafw/emr/deploy-asakusa.sh - 第2引数: デプロイメントアーカイブをS3に配置 で配置したデプロイメントアーカイブのS3パス
- 例:
s3://[mybucket]/asakusafw/asakusafw-example-basic-spark.tar.gz
- 例:
- 第1引数:
- 失敗時の動作
次へを選択
以上の手順でマスターノード上にAsakusa Frameworkのデプロイ処理が実行されます。
正常にデプロイが完了したことを確認するには、クラスター詳細画面の ステップ セクションを展開して、ステップ一覧に表示されるデプロイ用のステップを確認します。

デプロイ用のステップのステータスが 完了 と表示されればデプロイは成功です。
デプロイ用のステップのステータスが 失敗 と表示されデプロイが失敗した場合は、ダイアログの入力内容を確認してください。
もしくは、EMRクラスター上のステップのログを確認します。
ステップのログの確認方法は後述の アプリケーションの実行結果を確認 を参照してください。
| [2] | script-runner.jar はEMRが提供する、任意のスクリプトをマスターノード上で実行するためのツールです。 |
| [3] | deploy-asakusa.sh はAsakusa Frameworkが公開しているデプロイ用のスクリプトで、引数に指定したS3パスに配置されているデプロイメントアーカイブを $HOME/asakusa に展開します。 |
CLI¶
AWS CLI を使ったデプロイ例を以下に示します。
aws emr add-steps --cluster-id j-XXXXXXXXXXXXX --steps \
Type=CUSTOM_JAR,\
Name=DeployAsakusa,\
ActionOnFailure=CONTINUE,\
Jar=s3://elasticmapreduce/libs/script-runner/script-runner.jar,\
Args=s3://asakusafw/emr/deploy-asakusa.sh,\
s3://[mybucket]/asakusafw/asakusafw-example-basic-spark.tar.gz
ステップを登録すると、以下のようにステップIDが表示されます。 ステップIDはステップの実行結果を確認する場合などで使用します。
{
"StepIds": [
"s-XXXXXXXXXXXXX"
]
}
デプロイの結果を確認します。
aws emr describe-step --cluster-id j-XXXXXXXXXXXXX --step-id s-XXXXXXXXXXXXX \
--query 'Step.Status.State'
"COMPLETED"
バッチアプリケーションの実行¶
EMR環境にデプロイしたAsakusa Frameworkのバッチアプリケーションを実行します。
バッチアプリケーションの実行の流れは、以下のようになります。
以下、これらの手順について説明します。
アプリケーションの入力データをS3に配置¶
アプリケーションの入力データをS3に配置します。
入力データを配置するS3上のパスは、 デプロイメント構成の設定 の手順内で build.gradle に設定したDirect I/Oのファイルシステムパス ( directioRootFsPath の値 ) を基点とします。
サンプルアプリケーションの例では、プロジェクトに含まれるテストデータのディレクトリ src/test/example-dataset 配下のファイルを
このディレクトリ構造ごとS3のパスに配置します。
本書の例では、サンプルアプリケーションのテストデータを配置したS3のパスは以下のようになります。
s3://[mybucket]/app-data
├── master
│ └── item_info.csv
│ └── store_info.csv
└── sales
└── 2011-04-01.csv
コンソール¶
AWSマネジメントコンソールなどを使ってテストデータをアップロードします。 先述の デプロイメントアーカイブをS3に配置 などを参考にしてください。
CLI¶
以下は、AWS CLIによるテストデータのアップロードの例です。
aws s3 cp --recursive src/test/example-dataset s3://[mybucket]/app-data
Attention
上記例を参考にコマンドを入力する際は、必ずアップロード先のS3バケットのパスを実際に使用するパスに置き換えてください。
アプリケーションのステップを実行¶
ステップを通じてYAESSを実行することでアプリケーションをEMRクラスター上で実行します。
コンソール¶
クラスター詳細画面で以下の手順でデプロイを実行します。
画面上部の ステップの追加 ボタンを押下する
ステップの追加 ダイアログで以下の通りに入力し、 追加 ボタンを押下する
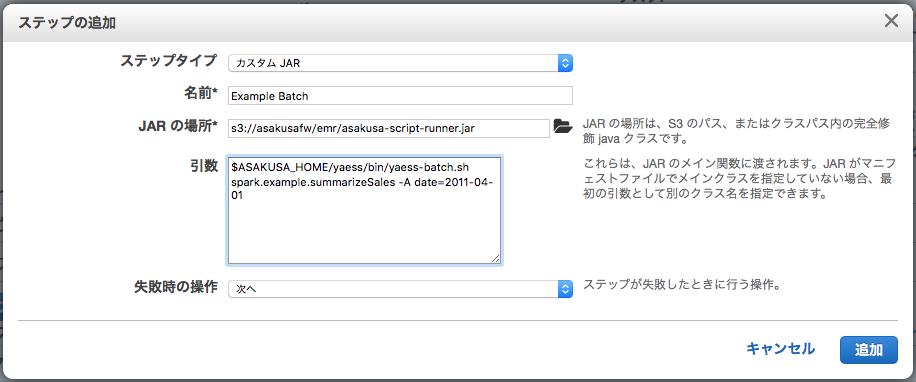
以上の手順でバッチアプリケーションが実行されます。
| [4] | asakusa-script-runner.jar はAsakusa Frameworkが公開しているツールで、 ${ASAKUSA_HOME} 配下の指定したスクリプトを実行します。 |
| [5] | Arguments に入力するYAESSコマンドは、通常コマンドライン上で yaess-batch.sh を実行する形式と同じです。例えばサンプルアプリケーションの実行では Asakusa Framework スタートガイド - サンプルアプリケーションの実行 の実行例のコマンド記述がそのまま使用できます。 |
CLI¶
AWS CLI を使ったバッチアプリケーション実行例を以下に示します。
aws emr add-steps --cluster-id j-XXXXXXXXXXXXX --steps \
Type=CUSTOM_JAR,\
Name=ExampleBatch,\
ActionOnFailure=CONTINUE,\
Jar=s3://asakusafw/emr/asakusa-script-runner.jar,\
Args='[$ASAKUSA_HOME/yaess/bin/yaess-batch.sh,spark.example.summarizeSales,-A,date=2011-04-01]'
Attention
Args の値全体は上の例のように '[ ]' で囲むことを推奨します。
こうすることで、 Args の値に key=value 形式や ${...} といった形式が含まれていてもそのまま記述できます。
また、 Args の値に複数の引数を指定する場合は、半角スペースではなくカンマ区切りになることに注意してください。
アプリケーションの実行結果を確認¶
アプリケーションのステップを実行 で実行したステップの実行結果を確認します。
コンソール¶
クラスター詳細画面の Steps セクションを展開して、ステップ一覧に表示されるデプロイ用のステップを確認します。
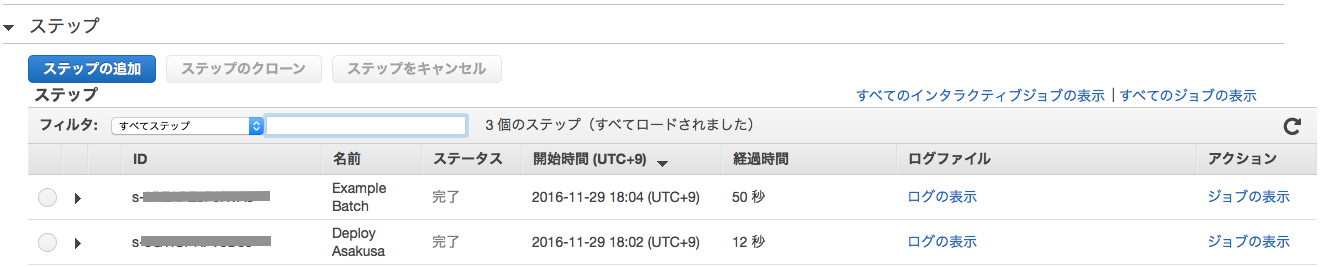
アプリケーションを実行したステップのステータスが 完了 と表示されればアプリケーションの実行は正常に完了しています。
ステップのステータスが 失敗 と表示されアプリケーションが失敗した場合は、ステップのログを確認します。
ステップのログは、ステップ一覧の列 ログファイル 上の ログの表示 を選択します。 このログは定期的(およそ5分ごと)にEMRクラスターの各ノードのログが収集されます。 ログの収集が終わっていない場合は、間隔をおいてリロードアイコンを押下します。
ログが収集されると、以下のようにログの種類ごとにリンクが表示されます。
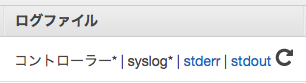
デフォルトの設定では、HadoopやSpark上のログは stdout, YAESSのログは stderr からそれぞれ確認できます。
CLI¶
AWS CLI を使ったステップのステータス確認の例を以下に示します。
aws emr describe-step --cluster-id j-XXXXXXXXXXXXX --step-id s-XXXXXXXXXXXXX \
--query 'Step.Status.State'
"COMPLETED"
ステップのログは定期的(およそ5分ごと)に収集され、 EMRクラスターの起動 の 起動パラメータ で --log-uri に指定したS3上のパスに配置されます。これを aws s3 コマンド等で取得して確認します。
アプリケーションの出力データをS3から取得¶
アプリケーションの設定に従ってデータ出力先のS3パスからデータを取得します。
サンプルアプリケーションの例では、入力データと出力データを配置するファイルシステムパスは同じです。
デプロイメント構成の設定 の手順内で build.gradle に設定したDirect I/O のファイルシステムパス ( directioRootFsPath の値 ) 配下になります。
本書の例では、サンプルアプリケーションの出力データのS3パスは以下のようになります。
s3://[mybucket]/app-data
└── result
├── category
│ └── result.csv
└── error
└── 2011-04-1.csv
コンソール¶
AWSマネジメントコンソールなどを使って出力データをダウンロードします。
CLI¶
AWS CLI を使ったファイルダウンロードの例を以下に示します。
aws s3 cp --recursive s3://[mybucket]/app-data/result /tmp/result
Attention
上記例を参考にコマンドを入力する際は、必ずダウンロード元のS3バケットのパスを実際に使用するパスに置き換えてください。
EMRクラスターの停止¶
使用が終わったEMRクラスターを停止します。
Warning
EMRクラスターを稼働し続けると、その分課金が発生し続けます。 不要になったEMRクラスターは忘れずに停止してください。
コンソール¶
クラスター詳細画面上部の Terminate ボタンを押下する。

クラスターを終了 ダイアログで 削除 ボタンを押下する
EMRクラスターが完全に停止すると、画面上部のステータスが 削除 と表示されます。
CLI¶
AWS CLI を使ったEMRクラスター停止の例を以下に示します。
aws emr terminate-clusters --cluster-ids j-XXXXXXXXXXXXX
クラスターが停止したことを確認します。
aws emr describe-cluster --cluster-id j-XXXXXXXXXXXXX \
--query 'Cluster.Status.State'
"TERMINATED"