YAESS JobQueue¶
Deprecated
本バージョンでは、 YAESS JobQueueの利用は非推奨となっています。
この文書では、シンプルなHadoopジョブの実行を制御するJobQueue(JobQueueサーバーおよび、それをYAESSと連携して利用するJobQueueクライアントプラグイン asakusa-yaess-jobqueue )の利用方法について解説します。
YAESS がリモートマシン上に配置したJobQueueサーバーを経由してバッチを実行することで、YAESS本体の設定とは独立してリモートマシンのリソースを簡易的に制御することが可能です。 また、JobQueueサーバーとJobQueueクライアントプラグインはHTTP経由で非同期的に通信し、ジョブの状況を監視するため、Hadoopのジョブ実行が長時間に渡る場合や、通信路が不安定な場合などに、組み込みで提供されているSSH経由での通信よりも安定した動作が見込めます。
JobQueueの概要¶
YAESS JobQueueが提供するコンポーネントとその機能について簡単に紹介します。
コンポーネント構成¶
JobQueueは主に2つのコンポーネントで構成されています。
- JobQueueサーバー
Hadoopのジョブを実行するサービスです。 HTTP経由でHadoopジョブ実行リクエストを受け取り、Hadoopコマンドを利用してジョブを起動します。 また、ジョブ実行リクエストを内部のキューに一度蓄えて、同時に実行可能なジョブ数を制御できます。
このコンポーネントは、Hadoopサービス群と通信するHadoopクライアントマシン上に配置します。
- JobQueueクライアントプラグイン
JobQueueサーバーにHadoopジョブ実行リクエストを送るクライアントで、 YAESSのHadoopジョブハンドラプラグインとして提供されます。 JobQueueサーバーを経由してYAESSからHadoopジョブを実行できます。
このコンポーネントは、YAESSを実行するマシン上にYAESSのプラグインとして配置します。
Hadoopジョブハンドラプラグインは、 YAESSユーザーガイド - Hadoopジョブの実行 で説明しているようなHadoopジョブの実行方法を決定します。 構成ファイルの
hadoopセクションのhadoopプロパティに使用するHadoopジョブハンドラプラグインを設定します。 構成ファイルの設定方法については後述の JobQueueを利用したHadoopジョブの実行 で解説します。
機能概要¶
JobQueueは以下のような機能を持っています。
- 同時実行数制御
- JobQueueサーバーから同時に実行可能なHadoopジョブの個数を制限できます。
- 標準出力の保存
- JobQueueサーバーからジョブを実行した際の標準出力および標準エラー出力を、ジョブごとに保存できます。
- HTTPS通信
- HTTPだけでなくHTTPSによる通信も可能です。
- ベーシック認証
- JobQueueサーバーとの通信時にHTTPのベーシック認証を利用可能です。
- ラウンドロビン処理
- 複数のJobQueueサーバーを登録すると、ラウンドロビン方式でバッチ内のHadoopジョブを振り分けて実行します。 一部のサーバーを利用不可能になった場合、そのサーバーをブラックリストに追加して同一バッチ内で利用しないようにします。
JobQueueを利用する際の構成例¶
以下はJobQueueを利用する際の構成例です。
単一構成¶
JobQueueサーバーを一台のマシンにインストールする場合、次のような構成をとります。
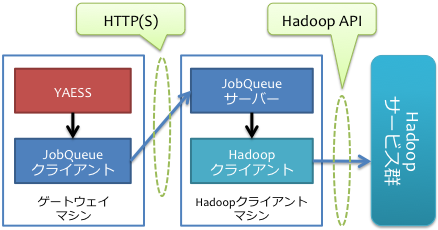
Hadoopコマンドを利用できるマシン(上図ではHadoopクライアントマシン)でJobQueueサーバーを実行し、そこに対してYAESSからJobQueueクライアントプラグインを利用して通信します。
冗長構成¶
単一構成 ではJobQueueサーバーが単一障害点になるという問題があるため、JobQueueサーバーを複数用意する冗長構成も検討してください。
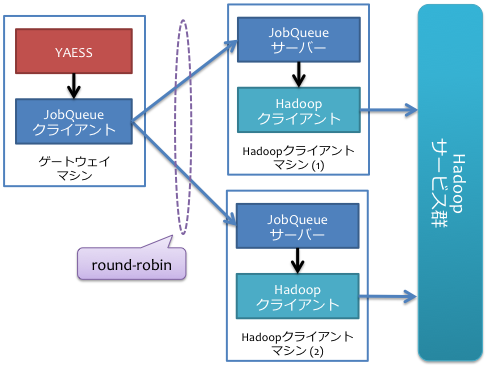
冗長構成では単一構成と異なりJobQueueサーバーを複数実行します。 上図では2台の異なるマシン上でそれぞれJobQueueサーバーを実行しています。 JobQueueクライアントプラグインに複数のJobQueueサーバーを登録すると、ラウンドロビン方式でそれぞれのJobQueueサーバーに対して交互にジョブ実行のリクエストを発行します。
JobQueueクライアントプラグインが、いずれかのJobQueueサーバーのダウンを検出すると、該当のサーバーをブラックリストに登録し、同一のバッチ内でそのサーバーを利用しないようにします。 JobQueueサーバーがダウンから復旧したら、次回以降のYAESSの実行ではそのサーバーを再度利用するようになります。
JobQueueのデプロイメント構成¶
JobQueueをデプロイするにあたって、まずはAsakusa Frameworkの全体構成を決定する必要があります。上述の JobQueueを利用する際の構成例 を参考に構成を検討してください。
また、Asakusa Frameworkが提供する外部システム連携の機能に従って、デプロイメント構成を検討します。 これについて、詳しくは システム構成の検討 を参考にしてください。 このドキュメントの「モジュール」の説明に対応づけると、JobQueueのコンポーネントは以下のモジュールに含まれることになります。
- JobQueueサーバー: Hadoopクライアントモジュール
- JobQueueクライアントプラグイン: バッチ起動モジュール
以降では運用環境に対して、JobQueueサーバーとJobQueueクライアントプラグインを導入し利用する方法について説明します。
JobQueueサーバーの利用方法¶
JobQueueサーバーは、Servlet API 3.0に対応したサーブレットコンテナ上のWebアプリケーションとして動作します。 ここでは、Apache Tomcat [1] Version 7(以下、Tomcatと表記します)を使ったJobQueueサーバーの利用方法を説明します。
Tomcatの構築手順やSSL、ベーシック認証の設定等は、Tomcatの公式ドキュメント [2] 等を参考にしてください。
以降、Tomcatをインストールしたディレクトリを、 ${CATALINA_HOME} と表記します。
| [1] | http://tomcat.apache.org |
| [2] | http://tomcat.apache.org/tomcat-7.0-doc/index.html |
JobQueueサーバー・コンポーネントのインストール¶
JobQueueサーバーに必要なコンポーネントを以下のページからダウンロードします。
ダウンロードが完了したら、以下の例を参考にしてJobQueueサーバーのコンポーネントを $ASAKUSA_HOME にインストールします (標準の ~/Downloads にダウンロードした場合の例です) 。
cd ~/Downloads
cp asakusa-jobqueue-server-*.tar.gz "$ASAKUSA_HOME"
cd "$ASAKUSA_HOME"
tar zxvf asakusa-jobqueue-server-*.tar.gz
find "$ASAKUSA_HOME" -name "*.sh" | xargs chmod u+x
JobQueueサーバーの設定¶
JobQueueサーバーの動作に必要な設定を行います。
$ASAKUSA_HOME/jobqueue/conf/jobqueue.properties をエディタで開き、修正を行なってください。
| 名前 | 値 |
|---|---|
core.worker |
同時実行可能なジョブのスロット数。YAESSの並列実行の設定やマシンリソースなどに応じて設定を行います。 |
hadoop.log.dir |
Hadoopジョブ実行時のログ出力先。 ここで指定したログディレクトリ配下にJobQueueサーバーがJobQueueクライアントプラグインからジョブ実行リクエストを受け付ける単位で生成される JRID(Job Request ID)の値でディレクトリが作成され、そのディレクトリ配下に JRIDはJobQueueクライアントプラグインやJobQueueサーバーが出力するログに出力されます。 問題分析の際にはこれらのログからエラートなったジョブのログを特定することができます。 このディレクトリ配下のディレクトリ/ファイルは自動的には削除されないため、必要に応じてクリーニングを行なってください。 |
Hadoopジョブの設定¶
JobQueueサーバーがキックするHadoopジョブに関する環境変数の設定を行います。
$ASAKUSA_HOME/jobqueue-hadoop/conf/env.sh をエディタで開き、修正を行なってください。
| 名前 | 値 |
|---|---|
JQ_HADOOP_PROPERTIES |
Hadoopジョブに追加のGenericオプションを指定することができます。 |
HADOOP_TMP_DIR |
ジョブの実行ごとに指定のディレクトリ以下にHadoopのテンポラリ領域を作成します。 省略された場合は、Hadoopのデフォルトのテンポラリ領域を使用し、全てのジョブで共有します。 このディレクトリはHadoopのジョブ実行毎にJRIDを持つサブディレクトリが作成され、このディレクトリ配下にジョブ実行時のワークファイルが作成されます。 ジョブ実行時のワークファイルはジョブが正常に終了した場合に自動的に削除しますが、ジョブが異常終了した場合には問題分析のため保持するようになっています。 |
以下は $ASAKUSA_HOME/jobqueue-hadoop/conf/env.sh の例です。
export JQ_HADOOP_PROPERTIES="-D com.example.property=example"
export HADOOP_TMP_DIR="/tmp/hadoop-${USER}"
Attention
使用するHadoopを明示的に指定する場合、ここで環境変数 HADOOP_CMD や HADOOP_HOME 設定する必要があります。
hadoop コマンドのパスが通っている場合、 hadoop コマンドを経由してHadoopを起動します。
JobQueueサーバーのデプロイ¶
$ASAKUSA_HOME/webapps/jobqueue.war をTomcatにデプロイしてください。
Tomcatにデプロイするには、 jobqueue.war ファイルを $CATALINA_HOME/webapps にコピーするか、次のようなコンテキスト設定ファイルで jobqueue.war ファイルのパスを指定してください。
例) $CATALINA_HOME/conf/Catalina/localhost/jobqueue.xml (環境変数 $ASAKUSA_HOME が /home/asakusa/asakusa の場合)
<Context docBase="/home/asakusa/asakusa/webapps/jobqueue.war" />
環境変数の設定¶
Tomcat起動時に、JobQueueサーバーの利用に必要となる環境変数を設定します。
~/.profile をエディタで開き、最下行に以下の定義を追加します。
export JAVA_HOME=/usr/lib/jvm/jdk-6
export ASAKUSA_HOME=$HOME/asakusa
export CATALINA_OPTS='-DapplyEvolutions.default=true'
~/.profile を保存した後、設定した環境変数をターミナル上のシェルに反映させるため、以下のコマンドを実行します。
. ~/.profile
JobQueueサーバーのログ出力¶
JobQueueサーバーはログ出力にLogback [3] を利用しています。
標準ではコンソールに出力されますが、出力先やログレベルを変更する場合にはLogbackの設定を変更する必要があります。 以下はLogbackの設定ファイル例です。
<configuration>
<conversionRule conversionWord="coloredLevel" converterClass="play.api.Logger$ColoredLevel" />
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>/tmp/asakusa/log/jobqueue-server.log</file>
<append>true</append>
<encoder>
<pattern>%d{yyyy/MM/dd HH:mm:ss} %-5level [%thread] %msg%n</pattern>
</encoder>
</appender>
<logger name="play" level="INFO" />
<logger name="application" level="INFO" />
<!-- Off these ones as they are annoying, and anyway we manage configuration ourself -->
<logger name="com.avaje.ebean.config.PropertyMapLoader" level="OFF" />
<logger name="com.avaje.ebeaninternal.server.core.XmlConfigLoader" level="OFF" />
<logger name="com.avaje.ebeaninternal.server.lib.BackgroundThread" level="OFF" />
<root level="INFO">
<appender-ref ref="FILE" />
</root>
</configuration>
JobQueueサーバーが設定ファイルを使用するには、上記の CATALINA_OPTS 環境変数に以下のように設定を追加します。
export CATALINA_OPTS='-DapplyEvolutions.default=true -Dlogger.file=/path/to/logger.xml'
| [3] | http://logback.qos.ch/ |
Tomcatの起動¶
ドキュメントに従ってTomcatを起動してください。
Attention
Tomcatは各デプロイメントガイドで説明したAsakusa Framework管理用のOSユーザー( ASAKUSA_USER )から実行するように設定してください。
動作確認¶
デプロイ先のURLのコンテキストルート [4] にアクセスして、次のようなJSONが出力されればJobQueueサーバーが正しく動作しています。
{"application":"asakusa-jobqueue","configurations":{"ASAKUSA_HOME":"/home/asakusa/asakusa","core.worker":4,"hadoop.log.dir":"/tmp/hadoop-asakusa/logs"}}
| [4] | コンテキストパスを jobqueue にした場合、 http://localhost:8080/jobqueue にアクセスしてください。 |
JobQueueクライアントプラグインの利用方法¶
JobQueueクライアントプラグインはYAESSのプラグインライブラリとして提供されています。ここではその導入と利用方法について説明します。
プラグインの登録¶
このプラグインを利用するには、 asakusa-yaess-jobqueue というプラグインライブラリをYAESSに登録します。
JobQueueクライアントプラグインは拡張モジュール ext-yaess-jobqueue-plugin として提供されています。
拡張モジュールのデプロイ方法については、 Asakusa Gradle Plugin ユーザーガイド を参照してください。
JobQueueを利用したHadoopジョブの実行¶
JobQueueを利用してHadoopジョブを実行する場合、構成ファイルの hadoop セクションに以下の内容を設定します。
| 名前 | 値 |
|---|---|
hadoop |
com.asakusafw.yaess.jobqueue.QueueHadoopScriptHandler |
hadoop.1.url |
JobQueueサーバーのURL |
hadoop.1.user |
JobQueueサーバーの認証ユーザー名 |
hadoop.1.password |
JobQueueサーバーの認証パスワード |
hadoop.timeout |
ジョブ登録時のタイムアウト (ミリ秒) |
hadoop.pollingInterval |
ジョブ状態の問い合わせ間隔 (ミリ秒) |
hadoop JobQueueクライアントプラグイン用のHadoopジョブハンドラプラグインクラスを指定します。
YAESS導入時には hadoop には標準的なハンドラクラスが設定されているので、この設定を変更します。
hadoop.1.url には、対象のJobQueueサーバーが動作しているコンテキストパスのルートまでを指定します。
現在のところ、プロトコルにはHTTPとHTTPSを利用可能で、URLに認証情報を含めることはできません。
hadoop.1.user と hadoop.1.password はそれぞれ上記URLに対する認証情報です。
認証を行わない場合、これらの認証情報は省略可能です。
hadoop.timeout と hadoop.pollingInterval はいずれも省略可能です。
それぞれJobQueueサーバーに対する通信のタイムアウトと問い合わせ間隔を指定します。
省略した場合、タイムアウトは 10000 、問い合わせ間隔は 1000 をそれぞれ既定値として利用します。
上記のうち、先頭の hadoop を除くすべての項目には ${変数名} という形式で、YAESSを起動した環境の環境変数を含められます。
Attention
JobQueueクライアントプラグイン用のHadoopジョブハンドラプラグインを指定した場合は、 hadoop.env から始まるプロパティを使用した環境変数の引渡しの仕組みは使用出来ません。
このため、デフォルトのYAESSの構成ファイルで設定されている hadoop.env.HADOOP_CMD や hadoop.env.ASAKUSA_HOME を設定している場合は、これらのプロパティを削除してください。
冗長構成用の設定¶
複数のJobQueueサーバーを利用してラウンドロビン方式でHadoopジョブを実行する場合、 JobQueueを利用したHadoopジョブの実行 に加えて以下の設定を追加します。
| 名前 | 値 |
|---|---|
hadoop.<n>.url |
JobQueueサーバーのURL |
hadoop.<n>.user |
JobQueueサーバーの認証ユーザー名 |
hadoop.<n>.password |
JobQueueサーバーの認証パスワード |
上記の <n> の部分には 2 以上の整数を指定し、それらに対してURL、ユーザー名、パスワードをそれぞれ指定します。
ただし、認証を必要としないJobQueueに対しては、ユーザー名とパスワードを省略可能です。
この <n> の箇所を 2 , 3 , … と次々増やしていくことで、より多くのJobQueueサーバーを登録できます。
これらはバッチ実行の際に、ラウンドロビン方式で順番に利用され、サーバーが動作していない際にはブラックリストに入れられます。
Attention
サーバーが動作していない場合にはラウンドロビンから外されますが、ジョブの実行中にサーバーがダウンした場合にはその場でジョブの実行が失敗します。
設定例¶
ジョブ実行クラスターの振り分けと組み合わせて利用する例¶
以下は ジョブ実行クラスターの振り分け とJobQueueを組み合わせて利用する設定例(構成ファイルの一部)です。
ローカル環境上の設定に対するサブハンドラには default を、JobQueueを経由するサブハンドラには jobqueue という名前をそれぞれ指定しています。
Jobqueueサーバーは2台の冗長構成をもち、それぞれBASIC認証を使用します。
# 振り分けハンドラ本体
hadoop = com.asakusafw.yaess.multidispatch.HadoopScriptHandlerDispatcher
hadoop.conf.directory = ${HOME}/.asakusa/multidispatch
# デフォルト設定を利用するサブハンドラ (default)
hadoop.default = com.asakusafw.yaess.basic.BasicHadoopScriptHandler
hadoop.default.resource = hadoop-default
hadoop.default.env.HADOOP_CMD = /usr/bin/hadoop
hadoop.default.env.ASAKUSA_HOME = ${ASAKUSA_HOME}
#JobQueueを利用するサブハンドラ (jobqueue)
hadoop.jobqueue = com.asakusafw.yaess.jobqueue.QueueHadoopScriptHandler
hadoop.jobqueue.resource = hadoop-jobqueue
hadoop.jobqueue.timeout = 30000
hadoop.jobqueue.pollingInterval = 500
#JobQueueサーバーは2台の冗長構成
hadoop.jobqueue.1.url = http://jobqueue-server1:8080/jobqueue
hadoop.jobqueue.1.user = asakusa1
hadoop.jobqueue.1.password = asakusa1
hadoop.jobqueue.2.url = http://jobqueue-server2:8080/jobqueue
hadoop.jobqueue.2.user = asakusa2
hadoop.jobqueue.2.password = asakusa2