Asakusa on Spark ユーザガイド¶
この文書では、 Asakusa Framework を使って作成したバッチアプリケーションを Apache Spark 上で実行する方法について説明します。
概要¶
Asakusa on Sparkは、Asakusa DSLを始めとするAsakusa Frameworkの開発基盤を利用して作成したバッチアプリケーションに対して、Sparkをその実行基盤として利用するための機能セットを提供します。
Sparkは高速で汎用性の高い、スケーラブルなデータ処理基盤を提供する目的で作成されたオープンソースソフトウェアです。いくつかの適用用途においてHadoop MapReduceよりも高速に動作する事例が公開されており、現在急速にその利用が拡大しています。
Asakusa Frameworkの適用領域においても、いくつかのケースでSparkを利用することで従来より高速にバッチアプリケーションが動作することを確認しています。Asakusa on Sparkによって、Asakusa Frameworkがより高速で汎用的なバッチアプリケーションの開発/実行基盤として利用できるようになることを目指しています。
構成¶
Asakusa on Sparkを利用する場合、従来のAsakusa Frameworkが提供するDSLやテスト機構をそのまま利用して開発を行います。 アプリケーションをビルドして運用環境向けの実行モジュール(デプロイメントアーカイブ)を作成する段階ではじめてSpark用のコンパイラを利用します。
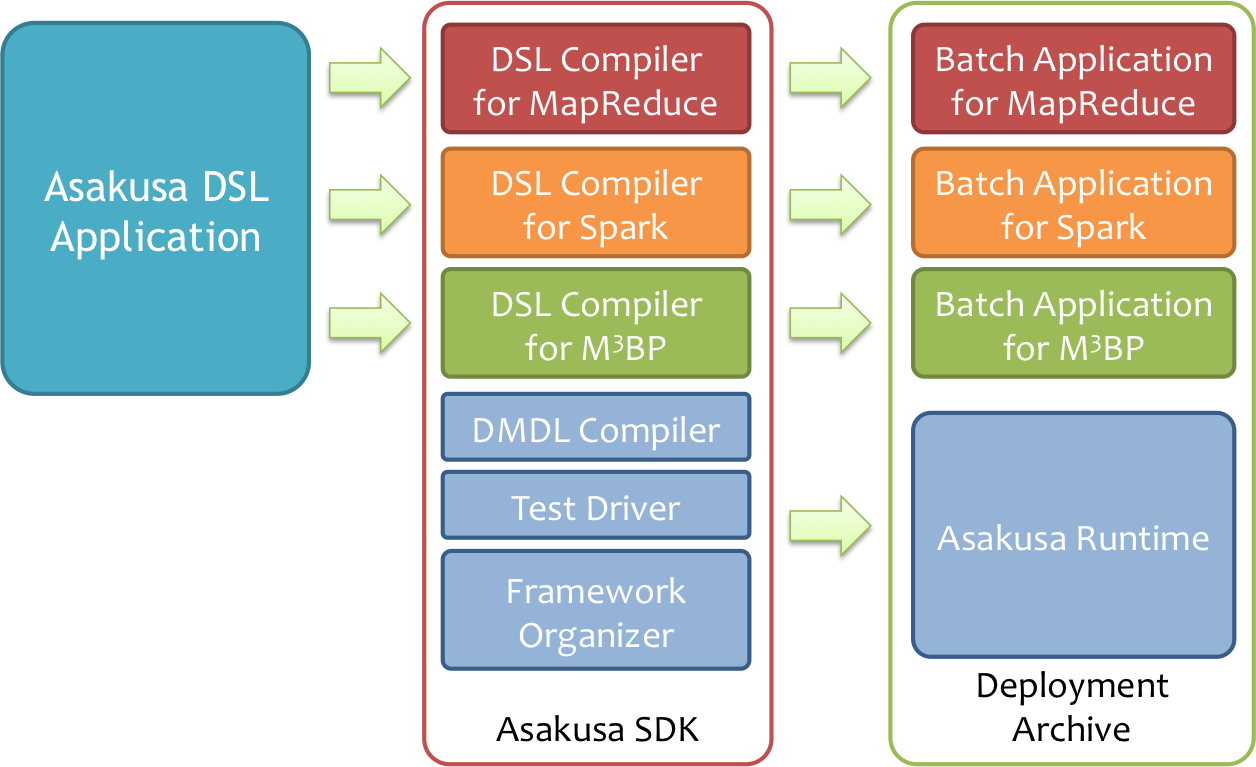
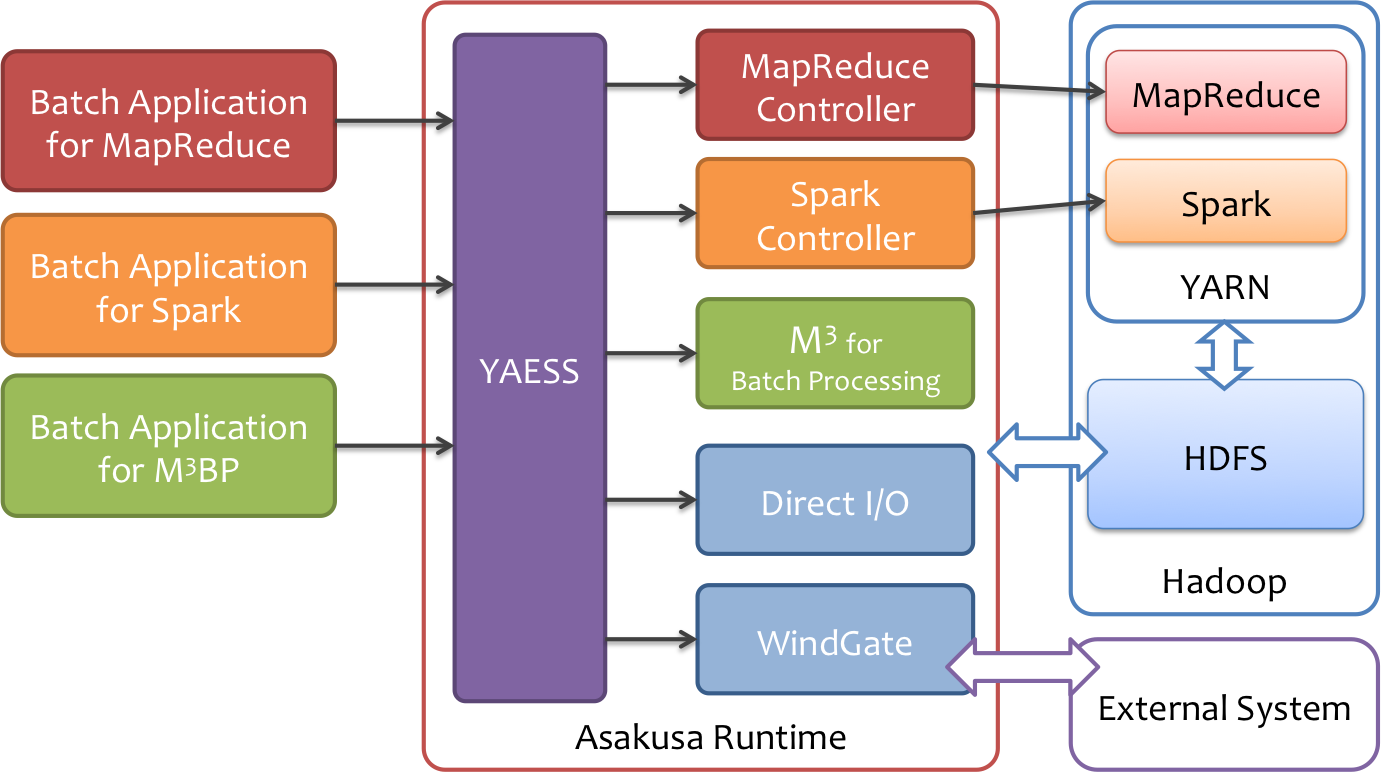
また、Asakusa DSL Compiler for Sparkで生成したバッチアプリケーションは、従来と同様にYAESSを利用して実行できます。
- Asakusa DSL
- 従来のAsakusa DSLやDMDLで記述したバッチアプリケーションは基本的に変更なしで、Asakusa DSL Compiler for Sparkを利用してSpark向けの実行モジュールを生成することができます。
- テスト機構
- 従来のAsakusa DSLのテスト方法と同様に、テストドライバーを利用してAsakusa DSLのテストを実行することができます。このとき、Sparkは特に利用しません。
- アプリケーションの実行
- 従来と同様、YAESSを利用してバッチアプリケーションを実行することができます。
- 外部システム連携
- Direct I/OやWindGateといった外部システム連携モジュールはSpark向けのバッチアプリケーションでもそのまま利用することができます。
Attention
Direct I/OやWindGateでHadoopの機能を利用するよう設定した場合は、Hadoopが動作する環境が併せて必要になります。
対応プラットフォーム¶
Spark¶
本バージョンのAsakusa on Sparkは、Spark 2.3.2 で動作を検証しています。
Attention
本バージョンのAsakusa on Sparkは、 Spark 1.6.x 以前のバージョンでは動作しません。
Hadoopディストリビューション¶
Asakusa on Sparkが動作を検証しているHadoopディストリビューションは、 対応プラットフォーム の「Hadoopディストリビューション」を参照してください。
開発環境の構築¶
新規に開発環境を構築する場合は、以下のドキュメントなどを参考にして開発環境を準備してください。
アプリケーションの開発¶
開発環境上で Asakusa Frameworkのバッチアプリケーションを開発し、Spark向けのアプリケーションをビルドする方法を見ていきます。
プロジェクトテンプレート¶
Asakusa on Sparkを利用する構成を持つアプリケーション開発用のプロジェクトテンプレートは、以下リンクからダウンロードします。
See also
プロジェクトテンプレートの構成や利用方法については、 Asakusa Gradle Plugin ユーザーガイド を参照してください。
サンプルアプリケーション¶
サンプルプログラム集 (GitHub) に含まれるプロジェクト example-basic-spark はAsakusa on Sparkを利用する基本的なサンプルアプリケーションプロジェクトです。
このプロジェクトはAsakusa on Spark用のプロジェクトテンプレートに対して、 Asakusa Framework スタートガイド などで説明しているサンプルアプリケーション「カテゴリー別売上金額集計バッチ」用のソースコードが追加されています。
Asakusa on Spark Gradle Plugin¶
Asakusa on Spark Gradle Pluginは、アプリケーションプロジェクトに対してAsakusa on Sparkのさまざまな機能を追加します。
プロジェクトテンプレート や サンプルアプリケーション で紹介したプロジェクトには、Asakusa on Spark Gradle Pluginがあらかじめ利用可能になっています。
その他のプロジェクトで Asakusa on Spark Gradle Pluginを有効にするには、アプリケーションプロジェクトのビルドスクリプト ( build.gradle )に対して以下の設定を追加します。
apply plugin: 'asakusafw-spark'
以下はAsakusa on Spark Gradle Pluginの設定を持つビルドスクリプトの例です。
group 'com.example'
buildscript {
repositories {
maven { url 'https://asakusafw.s3.amazonaws.com/maven/releases' }
}
dependencies {
classpath group: 'com.asakusafw.gradle', name: 'asakusa-distribution', version: '0.10.4'
}
}
apply plugin: 'asakusafw-sdk'
apply plugin: 'asakusafw-organizer'
apply plugin: 'asakusafw-spark'
apply plugin: 'eclipse'
See also
Asakusa on Spark Gradle Pluginのより詳細な情報は、 Asakusa Gradle Plugin リファレンス や Asakusa on Spark リファレンス などを参照してください。
アプリケーションのビルド¶
Asakusa on Spark Gradle Plugin を設定した状態で、Gradleタスク sparkCompileBatchapps を実行すると、Asakusa DSL Compiler for Sparkを利用し、Spark向けのバッチアプリケーションのビルドを実行します。
./gradlew sparkCompileBatchapps
sparkCompileBatchapps タスクを実行すると、アプリケーションプロジェクトの build/spark-batchapps 配下にビルド済みのバッチアプリケーションが生成されます。
標準の設定では、Asakusa DSL Compiler for Sparkよって生成したバッチアプリケーションは接頭辞に spark. が付与されます。
例えば、サンプルアプリケーションのバッチID example.summarizeSales の場合、Spark向けのバッチアプリケーションのバッチIDは spark.example.summarizeSales となります。
See also
Asakusa DSL Compiler for Sparkで利用可能な設定の詳細は、 Asakusa on Spark リファレンス を参照してください。
デプロイメントアーカイブの生成¶
Asakusa on Spark Gradle Plugin を設定した状態で、Asakusa Frameworkのデプロイメントアーカイブを作成すると、Hadoop MapReduce用とSpark用のバッチアプリケーションアーカイブを含むデプロイメントアーカイブを生成します。
デプロイメントアーカイブを生成するには Gradleの assemble タスクを実行します。
./gradlew assemble
Hint
Shafuを利用する場合は、プロジェクトを選択してコンテキストメニューから を選択します。
アプリケーションの実行¶
ここでは、Asakusa on Spark固有の実行環境の設定について説明します。
Asakusa Frameworkの実行環境の構築方法やバッチアプリケーションを実行する方法の基本的な流れは、 Asakusa Framework デプロイメントガイド などを参照してください。
Sparkのセットアップ¶
以降の説明で実施する手順は、Sparkがセットアップ済みのHadoopクラスターを対象とします。SparkのセットアップについてはSparkのドキュメントや利用するHadoopディストリビューションのドキュメント等を参考にして下さい。
実行コマンドの設定¶
Sparkを起動する際には、起動する対象の spark-submit コマンドの配置場所を環境変数に指定する必要があります。 Spark向けのバッチアプリケーションを実行する際には、次の手順で spark-submit コマンドを検索します。
- 環境変数
SPARK_CMDが設定されている場合、$SPARK_CMDを spark-submit コマンドとみなして利用します。 - spark-submit コマンドのパス ( 環境変数
PATH) が通っている場合、それを利用します。
上記の手順で spark-submit コマンドが見つからない場合、対象処理の実行に失敗します。
Asakusa on Sparkの実行に環境変数を利用する場合、 $ASAKUSA_HOME/spark/conf/env.sh 内でエクスポートして定義できます。
export SPARK_CMD=/opt/spark/bin/spark-submit
Tip
バッチアプリケーション実行時の環境変数は、YAESSプロファイルで設定することも可能です。
Asakusa on Sparkを利用する場合、コマンドラインジョブのプロファイル command.spark が利用できます。 $ASAKUSA_HOME/yaess/conf/yaess.properties に command.spark.env.SPARK_CMD といったような設定を追加することで、YAESSからSparkを実行する際に環境変数が設定されます。
YAESSのコマンドラインジョブの設定方法について詳しくは、 YAESSユーザーガイド - コマンドラインジョブの実行 などを参照してください。
spark-submit コマンドに対するオプション引数は、環境変数 ASAKUSA_SPARK_OPTS で指定できます。
以下は ASAKUSA_SPARK_OPTS の設定例です。
export ASAKUSA_SPARK_OPTS="--master yarn --deploy-mode cluster"
環境変数 SPARK_CMD_LAUNCHER は実行コマンドの先頭に任意のコマンド文字列を追加します。
バッチアプリケーションの実行¶
デプロイしたバッチアプリケーションをYAESSを使って実行します。
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh コマンドに実行するバッチIDとバッチ引数を指定してバッチを実行します。
標準の設定では、Spark向けのバッチアプリケーションはバッチIDの接頭辞に spark. が付与されているので、このバッチIDを指定します。
Attention
標準の設定では、バッチIDの接頭辞に spark. がついていないバッチIDは従来のHadoop MapReduce向けバッチアプリケーションです。YAESSの実行時にバッチIDの指定を間違えないよう注意してください。
例えば、サンプルアプリケーションを実行する場合は、以下のように yaess-batch.sh を実行します。
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh spark.example.summarizeSales -A date=2011-04-01
See also
サンプルアプリケーションのデプロイやデータの配置、実行結果の確認方法などは、 Asakusa Framework スタートガイド - サンプルアプリケーションの実行 を参照してください。
バッチアプリケーション実行時の設定¶
$ASAKUSA_HOME/spark/conf/spark.properties にはバッチアプリケーション実行時の設定を定義します。実行環境に応じて以下の値を設定してください。
com.asakusafw.spark.parallelismバッチアプリケーション実行時に、ステージごとの標準的なタスク分割数を指定します。
ステージの特性(推定データサイズや処理内容)によって、この分割数を元に実際のタスク分割数が決定されます。
標準的には、SparkのExecutorに割り当てた全コア数の1〜4倍程度を指定します。
このプロパティが設定されていない場合、
spark.default.parallelismの値を代わりに利用します。いずれのプロパティも設定されていない場合、下記の既定値を利用します。既定値:
2
See also
その他のバッチアプリケーション実行時の設定については、 Asakusa on Sparkの最適化設定 を参照してください。