25. Spark環境上のバッチ実行¶
このチュートリアルでは、Spark環境上でバッチアプリケーションを実行する方法を説明していきます。
25.1. YAESS¶
Asakusa Frameworkでは、バッチアプリケーションを実行するためのコマンドプログラムとして YAESS というツールを提供しています。
Asakusa Frameworkのバッチアプリケーションは、様々な実行プラットフォームで動作したり、外部連携ツールと連携して実行します。 YAESSはそのようなバッチアプリケーションに対して統一された方法で実行するコマンドラインインターフェースや設定管理の機構を提供します。
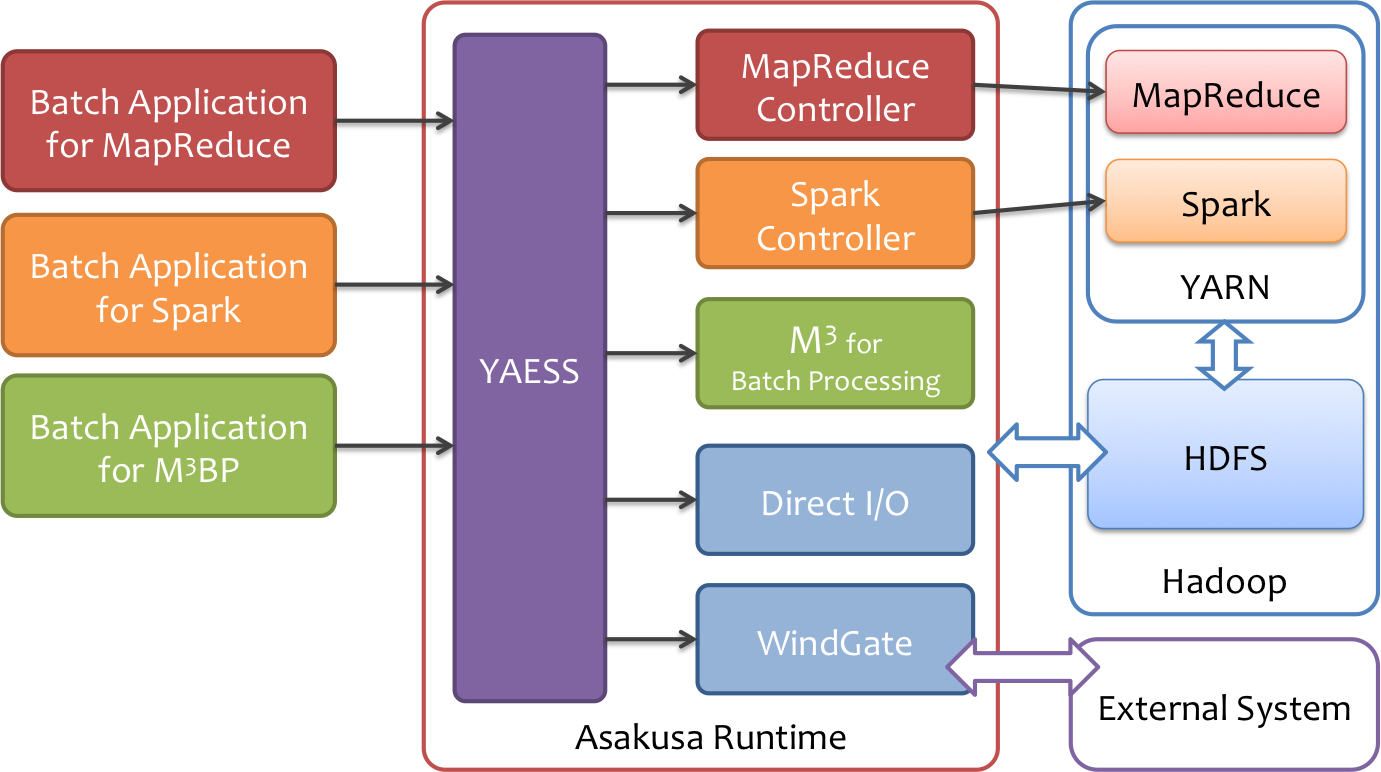
YAESSの代表的なコマンドは $ASAKUSA_HOME/yaess/bin/yaess-batch.sh です。 このコマンドに実行したいバッチのバッチIDとバッチ引数などのオプションを指定して実行することで、バッチアプリケーションが実行されます。
Spark環境向けにコンパイルされたバッチアプリケーションを実行するにはバッチIDの前にプレフィックス spark. を指定します。
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh spark.<バッチID> [-A <バッチ引数>]
Note
M3BP環境向けにコンパイルされたバッチアプリケーションを実行するにはバッチIDの前にプレフィックス m3bp. を指定します。
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh m3bp.<バッチID> [-A <バッチ引数>]
25.2. バッチアプリケーションの実行¶
それではYAESSを使ってデプロイしたバッチアプリケーションを実行してみましょう。
このチュートリアルで作成したバッチアプリケーションは バッチの作成 にて example.summarizeSales というバッチIDを指定しました。
また、このバッチは引数に処理対象の売上日時 date を指定し、この値に基づいて処理対象CSVファイルを特定します。
また、Sparkを利用するバッチアプリケーションは先で述べた通り、バッチIDの接頭辞に spark. を指定することを忘れないようにしてください。
ここでのバッチアプリケーションを実行するコマンドは、次のようになります。
$ASAKUSA_HOME/yaess/bin/yaess-batch.sh spark.example.summarizeSales -A date=2011-04-01
バッチの実行が成功すると、コマンドの標準出力の最終行に Finished: SUCCESS と出力されます。
...
INFO [YS-CORE-I01999] Finishing batch "spark.example.summarizeSales": batchId=spark.example.summarizeSales, elapsed=51,738ms
INFO [YS-BOOTSTRAP-I00999] Exiting YAESS: code=0, elapsed=51,790ms
Finished: SUCCESS
25.3. バッチアプリケーション実行結果の確認¶
Direct I/Oを使ったバッチアプリケーションの入出力ファイルを確認するためには、Direct I/Oの設定に従ったファイル一覧をリストアップするコマンド $ASAKUSA_HOME/directio/bin/list-file.sh が利用できます。
ここでは、アプリケーションの出力結果ディレクトリ result 以下のすべてのファイルを、サブディレクトリ含めてリストするようコマンドを実行してみます。
$ASAKUSA_HOME/directio/bin/list-file.sh result "**/*"
このコマンドを実行すると、以下のような結果が表示されます。
Starting List Direct I/O Files:
...
hdfs://<host:port>/user/asakusa/target/testing/directio/result/category
hdfs://<host:port>/user/asakusa/target/testing/directio/result/error
hdfs://<host:port>/user/asakusa/target/testing/directio/result/category/result.csv
hdfs://<host:port>/user/asakusa/target/testing/directio/result/error/2011-04-01.csv
ファイルの中身を表示するには、 hadoop fs -text コマンドに出力されたパスを指定します。
売上集計ファイル category/result.csv を表示するには、次のように実行します。
hadoop fs -text hdfs://<host:port>/user/asakusa/target/testing/directio/result/category/result.csv
指定したファイルの内容が表示されます。 売上データが商品マスタのカテゴリコード単位で集計され、売上合計の降順で整列されたCSVが出力されています。
カテゴリコード,販売数量,売上合計
1600,28,5400
1300,12,1596
1401,15,1470
また、このバッチでは処理の中で不正なレコードをチェックして、該当したエラーレコードをまとめてファイル error/2011-04-01.csv に出力します。
hadoop fs -text hdfs://<host:port>/user/asakusa/target/testing/directio/result/error/2011-04-01.csv
エラーチェックに該当したレコードの一覧は以下のように出力されます。
ファイル名,日時,店舗コード,商品コード,メッセージ
hdfs://<host:port>/user/asakusa/target/testing/directio/sales/2011-04-01.csv,2011-04-01 19:00:00,9999,4922010001000,店舗不明
hdfs://<host:port>/user/asakusa/target/testing/directio/sales/2011-04-01.csv,2011-04-01 10:00:00,0001,9999999999999,商品不明
hdfs://<host:port>/user/asakusa/target/testing/directio/sales/2011-04-01.csv,1990-01-01 10:40:00,0001,4922010001000,商品不明
25.3.1. その他の確認方法¶
バッチアプリケーション実行結果を確認する方法はYAESSのログやバッチアプリケーションの入出力ファイルを確認するほか、 HadoopやSparkが提供する次のような管理機能を利用することができます。
- Hadoop Resource Manager WebUI
- Hadoop yarn コマンド
- Spark History Server WebUI
詳しくはHadoopやSparkのドキュメントなどを参照してください。