リリースノート¶
Asakusa Frameworkのリリースノートです。 すべての変更点は Changelogs を参照してください。
Release 0.10.2¶
Sep 26, 2018
Asakusa Framework 0.10.2 documentation
新機能と主な変更点¶
- ビューAPIを以下の演算子に使用した場合に正しくコンパイルされないことがある不具合の修正
- マスタ確認演算子
- マスタ結合演算子
- マスタ分岐演算子
- マスタつき更新演算子
- Direct I/O の以下のフォーマットについて、長い文字列を含むデータを入力した場合にパースに失敗することがある不具合の修正
- broadcast joinアルゴリズムやビューAPIを使った結合演算子を含むデータフローが、まれなケースで循環参照を引き起こしコンパイルエラーとなる不具合の修正
- テストドライバーユーザーガイド 、およびテスト機能に関連する各ドキュメントの整理と改訂
- Asakusa Framework チュートリアル と Shafuのドキュメント を Shafu バージョン 0.7.0 の機能に合わせて改訂
その他、細かな機能改善およびバグフィックスが含まれます。 すべての変更点は Changelogs を参照してください。
互換性に関して¶
本リリースでは過去バージョンとの互換性に関する特別な情報はありません。
Release 0.10.1¶
Jun 27, 2018
Asakusa Framework 0.10.1 documentation
新機能と主な変更点¶
- ロギング演算子 を使用したアプリケーションが正しくコンパイルされないことがある不具合の修正
- マルチプロジェクト構成で eclipse タスク実行時、Eclipseプロジェクトファイルが正しく作成されないことがある動作を改善
- Asakusa CLI および Direct I/O CLI に日本語メッセージリソースを追加
- 対応プラットフォーム のアップデート ( Spark 2.3 , HDP 2.6.5 , Gradle 4.7 ) とこれに伴う修正
その他、細かな機能改善およびバグフィックスが含まれます。 すべての変更点は Changelogs を参照してください。
互換性に関して¶
本リリースでは過去バージョンとの互換性に関する特別な情報はありません。
Release 0.10.0¶
Nov 29, 2017
Asakusa Framework 0.10.0 documentation
はじめに¶
本バージョンでは ビューAPI などのAsakusa DSLに対するいくつかの拡張機能や、新しいコマンドラインインターフェース Asakusa CLI などの機能追加が行われました。 またこれらの機能を実現するため、Operator DSLコンパイラを刷新するなどAsakusa Frameworkの内部にも大幅な変更と拡張が行われました。
これらの機能拡張を検討し、また今後のAsakusa Framework開発の計画を検討する過程で、 Hadoop MapReduceを実行基盤として利用する Asakusa on MapReduce については今後も継続して Asakusa on Spark や Asakusa on M3BP といった他の実行エンジンと同等の機能や品質を維持することは困難であると判断し、 本バージョンから Asakusa on MapReduce を非推奨機能 として位置づけました。
このため、本バージョンで追加されたいくつかの機能拡張に、Asakusa on MapReduceは対応していません。
Asakusa on MapReduceの非推奨機化について詳しくは、本リリースノートの後半 Asakusa on MapReduceの非推奨化 にて説明しています。
新機能と主な変更点¶
ビューAPI¶
ビューAPI はAsakusa DSLの拡張機能で、データフロー上の任意の中間出力を、演算子から柔軟に参照するためのインターフェースを提供します。 ビューは主にバッチ全体の定数表を効率よく扱うためのしくみで、以下のような定数データを外部データソースから取り込んで演算子メソッドから利用できます。
以下は「消費税率」などの税率テーブルをデータベースなどに保持し、演算子内から参照するサンプルコード片です。
private static final StringOption KEY_CTAX = new StringOption("消費税");
/**
* 消費税を計算する。
* @param detail 販売明細
* @param taxTable 税率テーブル
*/
@Update
public void updateTax(
SalesDetail detail,
@Key(group = "name") GroupView<TaxEntry> taxTable) {
// 税率テーブルから「消費税」に関する情報を取得する
TaxEntry tax = taxTable.find(KEY_CTAX).get(0);
// 総額から本体価格を算出する
BigDecimal totalPrice = BigDecimal.valueOf(detail.getSellingPrice());
BigDecimal priceWithoutTax = totalPrice.divide(BigDecimal.ONE.add(tax.getRate()));
// ...
}
また、バッチ内で作成した中間データ(集計結果など)を上記と同様に定数表として参照したり、 柔軟なテーブル化の機能を利用して複雑な条件を伴う結合処理(例えばデータ範囲を条件とする結合)などを、効率よく実現したりすることが可能です。
ビューAPIの具体的な利用方法については、以下のドキュメントを参照してください。
Asakusa CLI¶
Asakusa CLI ( asakusa コマンド ) はバッチアプリケーションの開発支援機能、および運用機能を提供するコマンドラインインターフェースです。 Asakusa CLIは主に以下のような機能を提供します。
asakusa run - 簡易的なバッチアプリケーション実行ツール¶
asakusa run はバッチIDやバッチ引数を指定して、以下のようにバッチアプリケーションを実行します。
$ asakusa run m3bp.example.summarizeSales -A date=2011-04-01
Asakusa Frameworkは同様のバッチ実行ツールとして アプリケーションの実行 - YAESS を提供しています。 YAESSは様々な環境に対応するための数多くの設定や、実行状況を細粒度で示すため詳細なログ出力を行うといった特徴があります。 これに対して、 asakusa run はシンプルで必要最低限のコマンドやオプション、ログ出力を提供するといった特徴があります。
このため、特にバッチアプリケーションの開発中やテスト時には asakusa run の利用が適することが多いでしょう。
asakusa list - DSL情報を様々な観点や粒度でリスト化して表示¶
asakusa list はコンパイル済みのバッチアプリケーションに対して、 batch , jobflow , operator といった各DSLのレイヤ、および directio , windgate , hive といった利用する外部連携コンポーネント といった観点でバッチアプリケーションが持つ構成情報をリストとして表示します。
以下は、バッチアプリケーションが利用するDirect I/Oの入出力定義の一覧を表示する例です。
$ asakusa list directio input m3bp.example.summarizeSales
master::item_info.csv
master::store_info.csv
sales::**/${date}.csv
$ asakusa list directio output m3bp.example.summarizeSales
result/category::result.csv
result/error::${date}.csv
asakusa generate - DSL情報からデータフロー構造やコンパイル後の実行計画などのグラフ情報を生成¶
asakusa generate の機能例として、グラフ表示ツール Graphviz などと連携して 以下のようなバッチアプリケーションのデータフロー構造を示すフローグラフを生成することができます。
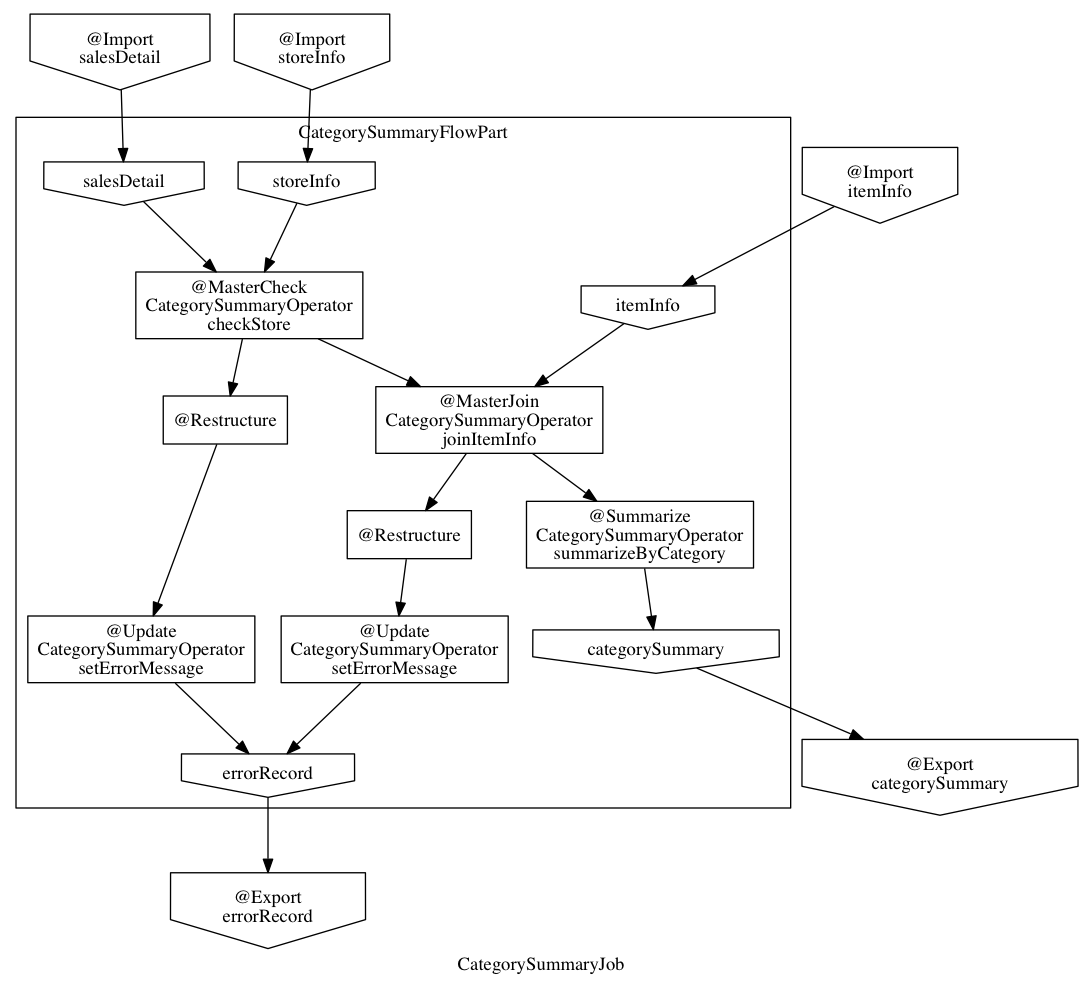
従来、グラフ表示ツールと連携する同様の機能はAsakusa on MapReduceの機能として提供していました。 Asakusa CLIが提供するこの機能はAsakusa on MapReduce以外の実行エンジンで利用することができます。
Asakusa CLIの具体的な利用方法については、以下のドキュメントを参照してください。
Direct I/O CLI (試験的機能)¶
Direct I/O CLI ( directio コマンド ) はDirect I/Oを利用する環境向けの運用ツールを提供するコマンドラインインターフェースです。 Direct I/O CLI は Asakusa CLIと類似のコマンド体系を持ち、Direct I/Oを利用する環境での運用で有用な以下の機能を提供します。
- directio {list|mkdir|get|put|delete|copy|move} - Direct I/Oデータソース上のファイルの操作
- directio configuration - Direct I/Oの設定情報を表示
- directio transaction - Direct I/O トランザクションの操作
Direct I/O CLIの具体的な利用方法については、以下のドキュメントを参照してください。
Asakusa Vanilla¶
Asakusa Vanilla は、主にアプリケーションのテスト用に設計された、Asakusa Framework実行エンジンのリファレンス実装です。 Asakusa Vanillaは単一ノード上でアプリケーションを実行し、軽量で比較的コンパイル速度が速く、実行時にJVM以外の環境を必要としない、といった特徴を持っています。
Asakusa VanillaはAsakusa Framework バージョン 0.9.0 から試験的機能として提供していましたが、 本バージョンより正式機能として アプリケーションのテスト - TestDriver で利用する標準の実行エンジンとして採用されました。 本バージョンから、標準の設定でテストドライバの実行時にAsakusa Vanillaの上でバッチアプリケーションが実行されます。
なお、従来のバージョンではテストドライバの標準の実行エンジンはAsakusa on MapReduceをベースにした「スモールジョブ実行エンジン」を使用していました。 本バージョンからAsakusa on MapReduceの非推奨化に伴い、スモールジョブ実行エンジンの利用も非推奨となりました。 詳しくは Asakusa on MapReduceの非推奨化 にて後述します。
Asakusa Vanillaの詳細やテストドライバ以外での利用方法については、以下のドキュメントを参照してください。
@Once, @Spill注釈¶
グループ結合演算子 や グループ整列演算子 では入力データを List として扱うため大きなグループを処理する場合にメモリが不足してしまう場合があり、
このような巨大な入力グループへの対応のために従来のバージョンでは InputBuffer.ESCAPE を指定し、メモリ外のストレージを一時的に利用する機能を提供していました。
本バージョンから提供される @Once 注釈, @Spill 注釈は InputBuffer.ESCAPE より柔軟に巨大な入力グループへの対応を行うことができます。
@Once 注釈は 引数の型に Iterable<...> を使用し、各要素の内容は一度だけしか読み出せないという制約の元に、
メモリ消費を抑え大きな入力グループを安全に取り扱うことができます。
また、 @Once 注釈はメモリ上でのみ処理を行うため InputBuffer.ESCAPE 利用時のようなパフォーマンス低下などの問題は発生しません。
以下、 @Once 注釈の利用例です。
@CoGroup
public void cogroupWithOnce(
@Key(group = "hogeCode") @Once Iterable<Hoge> hogeList,
@Key(group = "hogeId") @Once Iterable<Foo> fooList,
Result<Hoge> hogeResult,
Result<Foo> fooResult
) {
for (Hoge hoge : hogeList) {
...
}
for (Foo foo : fooList) {
...
}
}
@Spill 注釈は従来の InputBuffer.ESCAPE のように、メモリ外のストレージを利用して大きな入力グループを扱うための指定方法です。
InputBuffer.ESCAPE と同様のデメリットが存在しますが、
引数の型は List を利用することが可能で、 @Once 注釈では制約のある、リストに対する複数回アクセスやランダムアクセスが可能です。
また、従来の InputBuffer.ESCAPE は演算子の入力全体にかかる設定でしたが、
@Once 注釈, @Spill 注釈は 演算子の入力毎に指定することができます。
@Once 注釈, @Spill 注釈の詳細は、以下のドキュメントを参照してください。
組み込みHadoopライブラリー¶
従来までのバージョンでは、各コンポーネントや実行エンジンで利用するHadoopの設定方法の一部が統一されておらず、 各コンポーネントや実行エンジンごとに個別に異なる設定を行う必要がある、 また場合によってはHadoop環境を複数用意する必要がある、などの問題が発生していました。
本バージョンでは、Asakusa Framework全体で利用可能な「組み込みHadoopライブラリー」を提供しています。 これにより実行環境のHadoopと連携するための設定を統一し、また実行環境のHadoopと連携する必要がない場合には、 以下のようにビルドスクリプトの設定で組み込みHadoopライブラリーを追加するだけでバッチアプリケーション全体を実行することが可能になりました。
asakusafwOrganizer {
profiles.prod {
hadoop.embed true
}
}
一例として、WindGateを利用するには従来、実行環境のHadoopと連携する必要がない場合でもHadoop環境のセットアップや環境設定が必要でしたが、 本バージョンでは組み込みHadoopライブラリーを利用することでも実行可能になりました。 組み込みHadoopライブラリーを利用したWindGateの環境設定例は、 WindGateスタートガイド を参照してください。
またこの機能の追加に伴って、バージョン 0.9以前で Asakusa on M3BP を利用している場合、 本バージョンへの移行時にHadoopとの連携に関するビルドスクリプトの設定変更が必要です。 詳しくは、以下のドキュメントを参照してください。
その他詳細は、各コンポーネントや実行エンジンのドキュメントに記載のHadoop連携に関する説明を参照してください。
デプロイメント手順の変更¶
本バージョンでAsakusa CLIなどの機能が追加されたことに伴い、 Asakusa Frameworkのデプロイメントで使用するデプロイメントアーカイブの展開方法が変更になりました。
デプロイメントアーカイブの配置と展開後、以下のように java コマンド経由で $ASAKUSA_HOME/tools/bin/setup.jar を実行し、
展開したファイルに対して適切な実行権限などを設定します。
mkdir -p "$ASAKUSA_HOME"
cd "$ASAKUSA_HOME"
tar -xzf /path/to/asakusafw-*.tar.gz
java -jar $ASAKUSA_HOME/tools/bin/setup.jar
バージョン 0.9以前では、この部分は find "$ASAKUSA_HOME" -name "*.sh" | xargs chmod u+x のようなコマンドを実行していましたが、
本バージョンから展開後のファイル拡張子が一部変更されたため、この手順では正しくセットアップすることができません。
そのため、本バージョン以降は必ず上記のように $ASAKUSA_HOME/tools/bin/setup.jar を実行してセットアップを行ってください。
Asakusa Frameworkのデプロイメント手順については、以下のドキュメントを参照してください。
その他の変更点¶
- テストドライバ に 一時的なフロー記述に対するテスト 機能を追加。テストケースに演算子テスト用のデータフローを記述してテストを実行することができます。
- Asakusa Gradle Plguin に設定
asakusafw.sdk.yaessを追加。バッチアプリケーションに対するYAESSワークフロースクリプトの追加を設定可能(従来は常に追加)。 - Direct I/O Hive Hive連携モジュールで使用する Hiveのバージョン を
1.1.1から1.2.2にアップデート。 - Direct I/O Hive 特定プラットフォームでParquetの
DECIMAL型を正しく扱うことができない問題を修正。詳しくは後述の Direct I/O Hive - Parquetファイルフォーマットの変更 を参照してください。 - Asakusa on Spark Spark 2.0以降でYARN Clusterモードを使用するとバッチアプリケーションの成否にかかわらず常にエラーが返される問題の修正。
- 対応プラットフォーム 動作検証プラットフォームのアップデート。
その他、細かな機能改善およびバグフィックスが含まれます。 すべての変更点は Changelogs を参照してください。
非推奨化機能と削除された機能¶
本バージョンで非推奨化になった機能と削除された機能を以下に示します。 なおAsakusa on MapReduceについては Asakusa on MapReduceの非推奨化 にて後述します。
- バージョン 0.9.0で非推奨となったビルドスクリプト設定の削除。詳しくは後述の バージョン 0.8系以前からのマイグレーションについて を参照してください。
- Asakusa on M3BPの最適化設定
com.asakusafw.m3bp.buffer.accessの設定変更 (unsafeの使用 ) を非推奨化。 - Asakusa Gradle Plugin:非推奨機能 testRunBatchapp タスクを非推奨化。
Asakusa on MapReduceの非推奨化¶
はじめに で述べた通り、Hadoop MapReduceを実行基盤として利用する Asakusa on MapReduce は本バージョンから非推奨機能となりました。
実行エンジンについて¶
本バージョン、およびバージョン 0.10系 ( 0.10.1 , 0.10.2 , … ) については、Asakusa on MapReduceについては他の実行エンジンへの移行期間として位置づけており、 バージョン 0.9系 およびそれ以前に作成した Asakusa on MapReduce向けのバッチアプリケーションについては、 本バージョンでも通常のマイグレーション手順を実施することで動作するようになっています。
ただし、本バージョンおよび今後のバージョンで追加される機能拡張については、基本的にAsakusa on MapReduceには対応しない方針となります。 具体的には、本バージョンで追加になった以下の新機能はAsakusa on MapReduceでは利用できません。
本バージョン以降、バッチアプリケーションの実行エンジンについては Asakusa on Spark もしくは Asakusa on M3BP を利用することを推奨します。 各実行エンジンの利用方法や互換性に関する注意点については、Asakusa on Spark および Asakusa on M3BP のドキュメントを参照してください。
MapReduce関連機能について¶
また、Asakusa on MapReduceに関連する機能やMapReduceをベースとするその他の機能も、本バージョンから非推奨機能となります。 これらの機能には、スモールジョブ実行エンジンやAsakusa on MapReduce向けのDSL可視化、実行エンジンにMapReduceを利用したテスト機構などが含まれます。
本ドキュメントの Asakusa on MapReduce ページのドキュメントリンクに挙がっている機能はすべて非推奨機能となりますので、詳細はこのドキュメントページを確認してください。 本バージョン以降、これらの機能の多くは動作検証が行われないため、今後これらの機能の一部は利用できなくなる可能性があります。
これらの機能のうち、重要なものについては本バージョンで代替機能が追加され、標準で利用可能になっています。 詳しくは、バージョン 0.10.0 リリースノートの「新機能と主な変更点」を参照してください。
また、 Asakusa on Spark ではコンパイラ設定 spark.input.direct , spark.output.direct をそれぞれ false に指定することで、
MapReduce上でDirect I/Oの入出力を実行する機能が提供されていますが、本バージョンよりこの機能は非推奨機能となります。
今後の予定¶
Asakusa Framework バージョン 0.10系では、本バージョンと同様に上述の制約に基づいてAsakusa on MapReduceを利用することができます。 Asakusa on MapReduceを利用可能なバージョンを継続して提供するため、今後しばらくはバージョン 0.10系 のメンテナンスリリースを実施していく予定です。
将来リリース予定の Asakusa Framework バージョン 1.0 では、Asakusa on MapReduceおよびMapReduce関連機能は削除され、これらの機能は利用できなくなる予定です。
互換性に関して¶
ここでは過去バージョンからのマイグレーション時に確認すべき変更点について説明します。
標準のマイグレーション手順については以下のドキュメントで説明しています。
Asakusa Frameworkのデプロイメント手順の変更¶
本バージョンでAsakusa CLIなどの機能が追加されたことに伴い、Asakusa Frameworkのデプロイメント手順が一部変更になりました。 詳細は本リリースノートの デプロイメント手順の変更 の項を参照してください。
Asakusa on M3BP のHadoop連携に関する設定の変更¶
過去バージョンの Asakusa on M3BP を利用している場合、 本バージョンから Hadoopと連携するための設定方法が変更になりました。 詳細は本リリースノートの 組み込みHadoopライブラリー の項を参照してください。
また本件の対応のために、ビルドスクリプト build.gradle の修正が必要になります。
詳しくは Asakusa Gradle Plugin バージョン 0.10系 の変更点 を参照してください。
Direct I/O Hive - Parquetファイルフォーマットの変更¶
本バージョンでは Direct I/O Hive 利用時に特定プラットフォームでParquetの DECIMAL 型を正しく扱うことができない問題が修正されました。
この変更に伴い、過去バージョンで作成したParquetファイルに対するデータフォーマットの互換性が失われました。
過去バージョンのDirect I/O Hiveで作成したParquetファイルは、本バージョン以降のDirect I/O Hiveで正しく読み込むことが出来ない可能性があります。
過去バージョンで作成したParquetデータを本バージョン以降で読み込むためには、 過去バージョンで作成したParquetファイルをいったん他のフォーマットに変更するなど、本バージョンのDirect I/Oで処理可能な形式に変換してデータの移行を行ってください。
バージョン 0.8系以前からのマイグレーションについて¶
本バージョンでは、バージョン 0.9.0で非推奨となった以下の古いビルドスクリプト設定が利用できなくなりました。
- ディストリビューションプラグイン以外のAsakusa Gradle Plugin以外の定義。必ずディストリビューションプラグインを使用してください。
- SDKアーティファクトを使用した依存性定義。Asakusa Frameworkが提供するアプリケーションライブラリの追加は、
asakusafwブロック配下のsdkで指定してください。
これらの機能とビルドスクリプトの変更方法については、 Asakusa Gradle Plugin バージョン 0.9系 の変更点 に記載しています。 バージョン 0.8系以前から本バージョンにマイグレーションを行う場合、必ずこのドキュメントの内容に従って アプリケーションプロジェクトのビルドスクリプトを変更してください。 また、アプリケーションプロジェクト全体のマイグレーション手順については、 Asakusa Gradle Plugin マイグレーションガイド を参照してください。